K-Nearest Neighbors – Iris Flowers.
.
Introduction.
This project uses the K-Nearest Neighbors (KNN) algorithm to classify Iris flowers based on their sepal and petal measurements. The dataset used in this project is the Iris Dataset, which includes samples «IRIS.DATA» of Iris flowers, each with four features: sepal length, sepal width, petal length, and petal width. (Names flowers: Versicolor, Virginica and Setosa).
.
Distribution DataSet – Iris.data
.
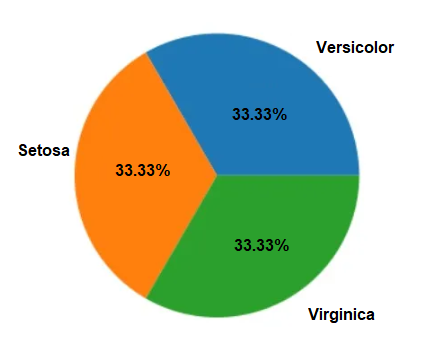
Example only a segment of DataSet : Iris. data
.
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
.
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
5.7,2.8,4.5,1.3,Iris-versicolor
.
6.5,3.2,5.1,2.0,Iris-virginica
6.4,2.7,5.3,1.9,Iris-virginica
6.8,3.0,5.5,2.1,Iris-virginica
5.7,2.5,5.0,2.0,Iris-virginica
5.8,2.8,5.1,2.4,Iris-virginica
6.4,3.2,5.3,2.3,Iris-virginica
.
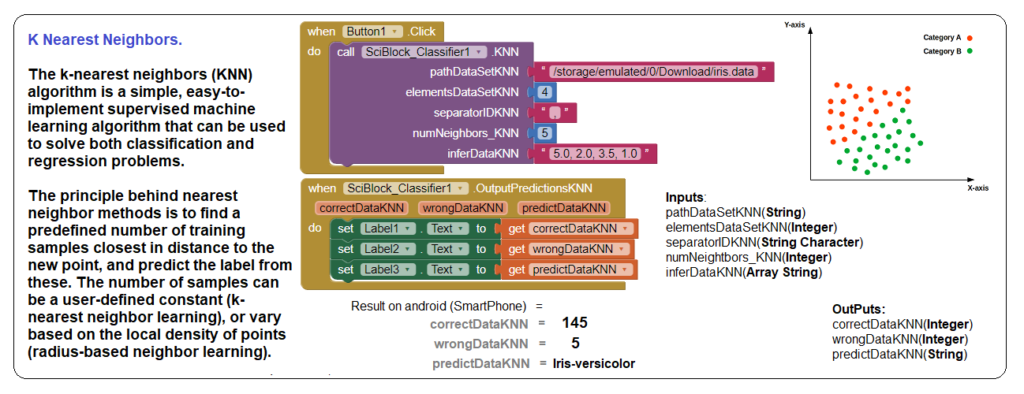
Using extension with K-Nearest Neighbors.
.
Input Data = ( 5.0, 2.0, 3.5, 1.0 ).
.
.
Conclusions.
.
In this example we can see that the KNN algorithm gives good prediction or inference results with the input data based on the Iris.data DataSet.
NOTE: This DataSet is only an example and any other DataSet can be used depending on the project being treated.